
Text-to-Image (T2I) 生成模型是一種能夠根據文本描述生成圖像的技術。這些模型主要分為兩大類:Autoregression Model 和 Diffusion Model。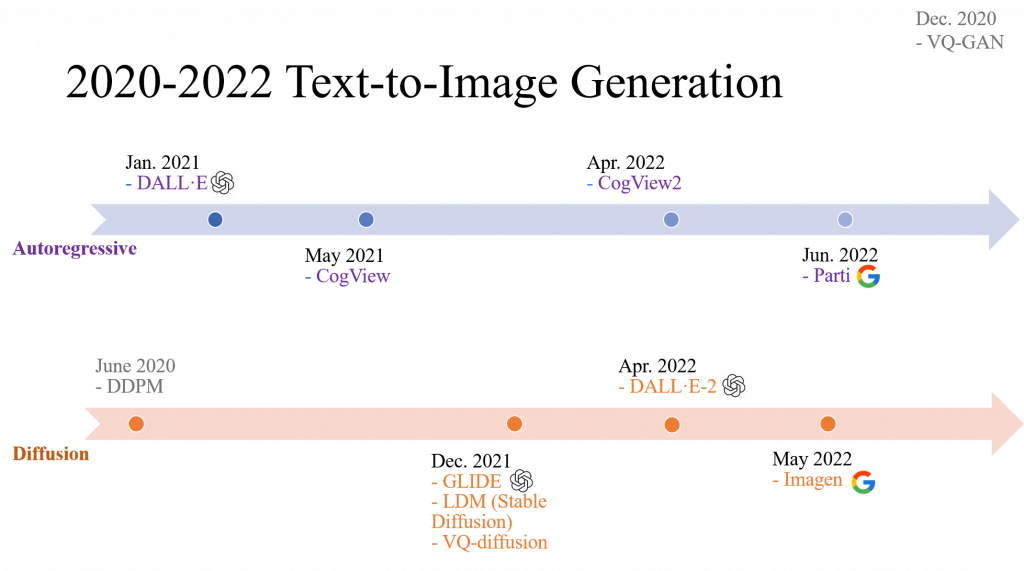
Imagen 主要模塊及工作流程如圖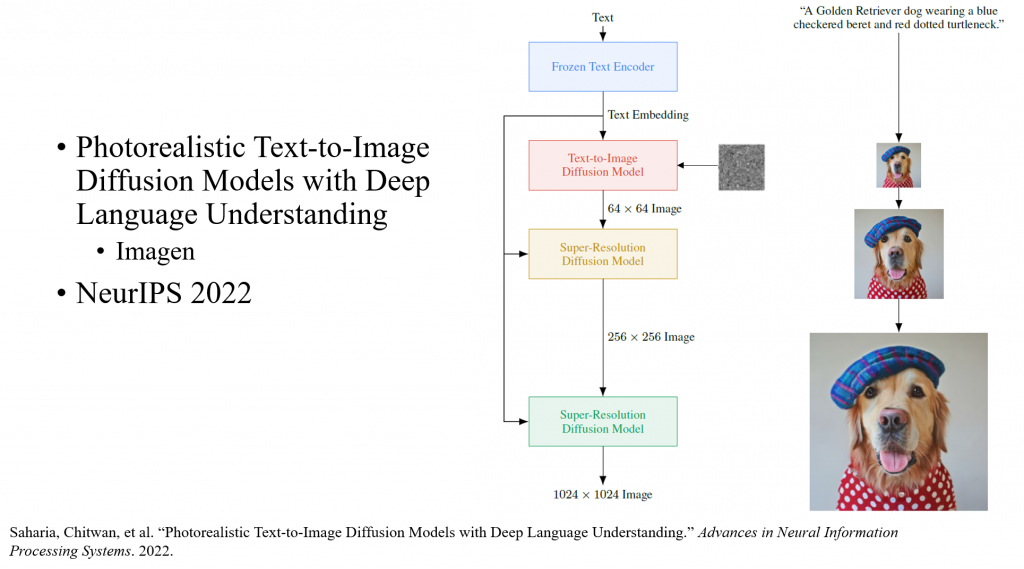
Google 他們有實驗過 3 種 Frozen pretrained text encoders: BERT, T5 and CLIP.
人類比較喜歡 T5-XXL encoders > CLIP text encoders

因為Diffusion直接推高解析度的圖片會花很久時間,而且容易生成品質差。
他們會訓練 2 個擴散模型,專門處理 super resolution:
所以他們改成
其實看到這篇以為是可以隨意應用的新的技術和創新,後來看到訓練這麼多模型就大概了解他們研究的範圍、深度或適用性可能有限。尤其T5模型又大又難訓練,真的需要錢錢才能使用這個模型。
在深入了解DALL·E2 的工作原理之前,讓我們先大致了解一下DALL·E2 如何生成圖像。
在最簡單的理解,DALL·E2 的工作非常簡單: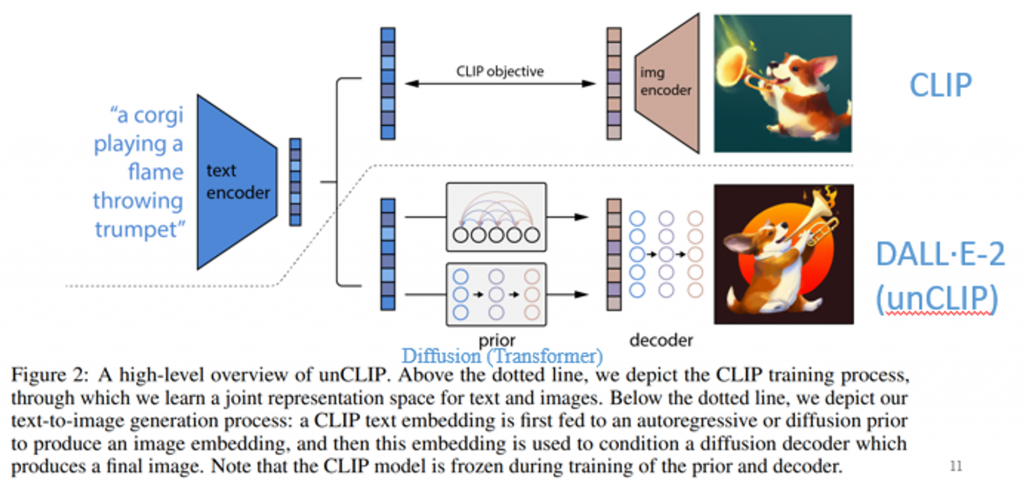
這篇論文裏CLIP的這個模型一直都是鎖住的,是不會進行任何訓練和fine-tune。
DALL·E2 沒有用attention layers,所以說在做inference的時候,可以用在任何的一個尺寸上,不需要擔心說這個序列長度必須得保持一致。
DALL·E2 的主要方法主要建立在 CLIP 上,但跟 CLIP 做的事情是相反,所以也被稱作 unCLIP。但因為沒有開源,所以實際運作方法可能要再看一下其他資源。
Reference: https://arxiv.org/abs/2102.12092

 iThome鐵人賽
iThome鐵人賽